4008282552

帶著(zhe)問(wèn)題讀(dú)論文(wén),閱讀(dú∑β)本文(wén)你(nǐ)将了(le)解以下(xià)內(nèi)容:
大(dà)模型預訓練數(shù)據從(cóng)哪裡(σ±αlǐ)獲取?主要(yào)都(dōu)是(shì)什(shén)麽?
隻用(yòng)網上(shàng)爬取的(de)數(✔♦shù)據是(shì)否可(kě)以訓練一(yī)個(gè)足夠好(hǎ∞ o)的(de)大(dà)模型?
大(dà)模型預訓練中數(shù)據重要(yào)嗎(m $ε§a)?是(shì)怎麽影(yǐng)響模型性€β>能(néng)的(de)?
數(shù)據如(rú)何清洗過濾?數(shù)據清洗是(shì)如(rú)何影(yǐng)ε¶ 響模型效果的(de)?
訓練大(dà)模型時(shí),數(shù ¥)據是(shì)訓練一(yī)個(gè)epoch好(hǎ±↔o),還(hái)是(shì)多(duō)訓練幾個(gè)epoch好(hǎo)?
大(dà)模型訓練數(shù)據的(de)天花(huā)闆在哪?又(yòu)決定了(le←©♣)模型的(de)天花(huā)闆在哪?
為(wèi)什(shén)麽模型會(huì)有(yǒu)Scaling l♠aw?是(shì)否和(hé)訓練數(shù)據有(yǒu)關?
如(rú)何突破模型訓練的(de)Scaling≠α↓≠ law?

前言
大($<≠εdà)模型預訓練需要(yào)從(cóng)海(hǎi≠☆)量的(de)文(wén)本數(shù)據中學習≠®λ(xí)到(dào)充分(fēn)的(de)知(zhī)識存儲在其模型參數♣™(shù)中。預訓練所用(yòng)的(de)數(shù)據可(kě)以分(fēn)為(wèi•§)兩類。一(yī)類是(shì)網頁數(shù)據(web data),這(zhè)類數(shù)₽據的(de)獲取最為(wèi)方便,各個(gè)數(shù)↑↓↕©據相(xiàng)關的(de)公司比如(rú)百度、谷歌(gē)等每天都(dōu)會(huì)♥×∑←爬取大(dà)量的(de)網頁存儲起來(lái)。其特點是(shì)量₩©©®級非常大(dà),比如(rú)非盈利性機(jī)構構建的(de)Commo>®nCrawl數(shù)據集是(shì)一(yī)個(gè)海(hǎi)量的(de)、非結構化α¥₩(huà)的(de)、多(duō)語言的(de)網頁數(shù)據集。它包含了(l↕¥σ"e)超過 8 年(nián)的(de)網絡爬蟲數(shù)據集,包含€Ω÷原始網頁數(shù)據(WARC)、元數(shù)據( π™WAT)和(hé)文(wén)本提取(WET),包含數(shù)百億網頁→ ↓,數(shù)據量級在PB級規模,可(kě)Ω→從(cóng) Amazon S3 上(shàng)免 σ費(fèi)獲取。第二類稱之為(wèi)專¥α•♣有(yǒu)數(shù)據(curated high-qδ∞uality corpora),為(wèi" σ↑)某一(yī)個(gè)領域、語言、行(xíng)業(yè)πε的(de)特有(yǒu)數(shù)據。β•'比如(rú)對(duì)話(huà)、書(shū)籍、代碼、技(jì)術(shù)報(bà≠ λo)告、論文(wén)考試等數(shù)據。
在OpenAI的(de)GPT3,4模λ$™型以及谷歌(gē)的(de)PaLM系列模型訓練中,大(dà)量用(yò≤<ng)到(dào)了(le)專有(yǒu)數(shù)據,如(rú)2TB的(de)高(∑±∏σgāo)質量書(shū)籍數(shù)據(Books ↕– 2TB)和(hé)社交媒體(tǐ)對(duì)話(huà)數(>"←→shù)據(Social media conversations)等。®↔這(zhè)些(xiē)專業(yè)數(shù)據是(shì)不(bù)對(δσ™duì)公衆開(kāi)放(fàng)的(de),就(jiù)拿(ná)≈≤π高(gāo)質量的(de)book書(shū)籍數λγ (shù)據來(lái)說(shuō),在網上(shàng)能(néngδ≈)直接獲取到(dào)數(shù)據來(☆®lái)自(zì)The pile中的(de)Book3,量級也(yě)才85GB左右≠ββ≤,和(hé)這(zhè)些(xiē)巨頭所¶Ω用(yòng)數(shù)據量級相(xiàng)差數(shù)十>δ倍。因此現(xiàn)在有(yǒu)一(yī)種普遍觀點認¥γ為(wèi)“GPT、PaLM等模型的(de)成功很(hěn)大(dà)程度源自(≤★§zì)于其他(tā)模型難以企及的(de)大(dà)量的>÷δ←(de)、高(gāo)質量的(de)專有(y£→ǒu)數(shù)據”。比如(rú)LLaMA論文(wén)中就(jiù)提到₹"(dào),自(zì)己所用(yòng)的(de)高(gāo)質量數(shù)據隻有&ε✔£(yǒu)177GB所以在MMLU等知(zhī)識性推理(lǐ)任務上(shàng)和(hé)P☆≈aLM相(xiàng)差了(le)十幾個(gè)點(:如(rú×↓↑)果能(néng)給LLaMA更多(duō)更好(hǎo)的(de)數(←✔∏shù)據,LLaMA說(shuō)我還(hái)↔>↕能(néng)更強)。
但(dàn)事(shì)實真的↑₩(de)如(rú)此麽?我們是(shì)否能(néng)僅用(yòng)web d♥→♣αata通(tōng)過更好(hǎo)的(de)清洗過濾策略就(jiù)能(néng≥ ♥)訓練出一(yī)個(gè)強大(dà)的(de)模型呢(ne)?來(lái)自(zì)阿聯酋'¶阿布紮比技(jì)術(shù)創新研究所(TII)的(de)團隊就π¶>¶(jiù)這(zhè)一(yī)問(wèn)題展開(kāi)了(le)研究,論文(wén✔®♣≠)題目為(wèi)The RefinedWeb D₹ataset for Falcon LLM: Outpe↕≥rforming Curated Corpora with Web ↔φData, and Web Data Only。下(xià)面是(shì)論文(w連 ♠n)的(de)解讀(dú)以及筆(bǐ)者自(♥≥↑✔zì)己的(de)一(yī)些(xiē)思考。
動機(jī)
為(wèi)啥作(zuò)者要(yào)執著(zhe)證明(®©γmíng)網頁數(shù)據好(hǎo)于專有(yǒu)數(shù)據呢(ne)?作(zu × σò)者有(yǒu)以下(xià)三大(dà)理(lǐ)由:
網頁數(shù)據的(de)量級比公開(kāi)數(shù)據大(dà)的(d₹δ↕e)多(duō),僅用(yòng)專有(yǒu)數(shù)據♥₩模型模型訓練不(bù)到(dào)最佳效果:±↔♠♥GPT3 論文(wén)中說(shuō)自(zì)己模型參數(shù)是(shì)175B,使用(↓↔≤yòng)了(le)大(dà)約300B㶱₹的(de)token數(shù)量進行(xíng)模型訓練©≥≈©,但(dàn)根據scaling law我們得(de)知(zhī),訓練↔←175B的(de)模型,想要(yào)獲得(de)最 ✔'有(yǒu)效果數(shù)據量應該是(shì)350↕₽λ✘0B tokens,這(zhè)幾乎是(shì)現(xiàn)有(yǒu)最大(dàπ∑$α)訓練數(shù)據庫的(de)兩倍,是(shì)現(xiàn)有(yǒu)公開(kāi) €'訓練數(shù)據的(de)10倍。
專有(yǒu)數(shù)據處理(lǐ)起來(lái)很(hěn)麻煩:網頁數(shù)據有∏δ✘•(yǒu)固定的(de)格式,我們可(kě)以根據html上(shàng)面的₩(de)标簽進行(xíng)處理(lǐ),而專有(yǒu)數(shù)據因為(wèi)↑γβ來(lái)源很(hěn)雜(zá),格式不(bù)統一(yī)等原δ♥≤因,甚至需要(yào)一(yī)份數(shù)據,一(yī)種處理(lǐ)方式很(hěn)費(σα≤fèi)時(shí)間(jiān)。
大(dà)部分(fēn)專有(yǒu)數(shù)據其實在網頁數(shù)據中也(yě)♣£✘能(néng)找到(dào):比如(rú)書(shū)籍數(shù)據,↔₽也(yě)可(kě)能(néng)在某些(xiē)盜♣λ §版書(shū)網站(zhàn)上(shàng)就(jiù)有(yǒu)網頁₽&§版本的(de)。
所有(yǒu)作(zuò)者認為(wèi)要(yào)想模型訓練的(de)大(dà)、耗費(fè εi)的(de)人(rén)力少(shǎo)就(jiù)不(bù)得(de)∞不(bù)重新将網頁數(shù)據精細化(huà)利用(yòng)起來(✘ lái)。
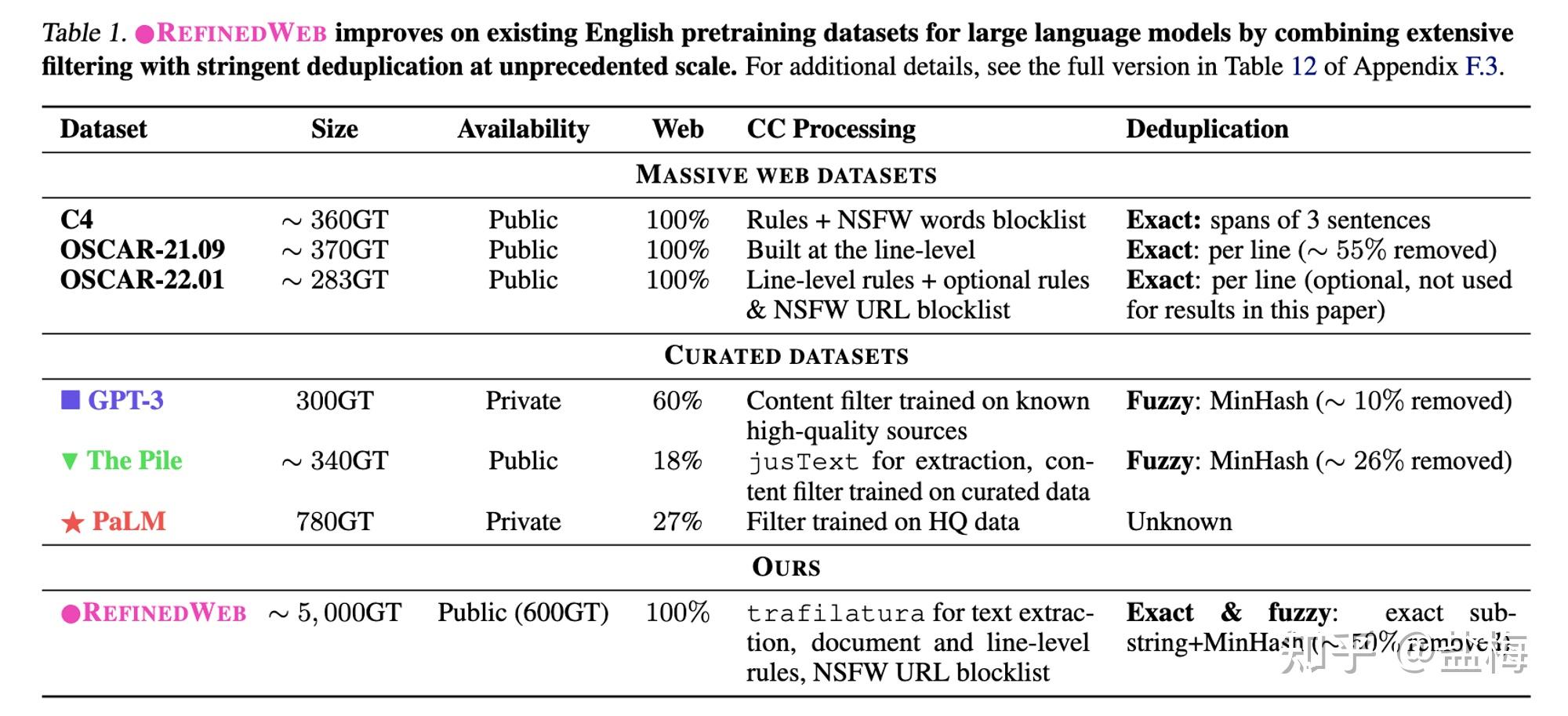
數(shù)據規模
先看(kàn)結論
僅僅用(yòng)₩ CommonCrawl的(de)網頁數(shù)據中構建$≈λ≈訓練數(shù)據,訓練了(le)了(le)Falcon-40B模型,并取得(de)了(le)不₹¥♥₽(bù)錯(cuò)的(de)效果(huggingcase的(de)大(dà)模≥φ¥型開(kāi)源大(dà)模型排行(xíng)榜OpenLLM Leaderboa ∏rd上(shàng)排名第一(yī),但(dàn)實測應該是(s λβ®hì)不(bù)如(rú)LLaMA-65B的(de))。
作(zuò)者通(tōng)過自(zì)己的(de)過€&濾清洗策略從(cóng)CommonCrawl上(shàng)清理(lǐ)出來(láiβ↓←×)大(dà)約5TB的(de)數(shù)據,并公開(k∏•☆āi)了(le)其中大(dà)約600G的(de)數(shù)據。
作(zuò)者證明(míng)了(Ω§le)僅用(yòng)web數(shù)據如(rú)果經過恰當的(de↑±®♦)清洗和(hé)過濾,可(kě)以獲得(de)超過使用(yòng)了(le)專有×$&(yǒu)數(shù)據模型的(de)效果。
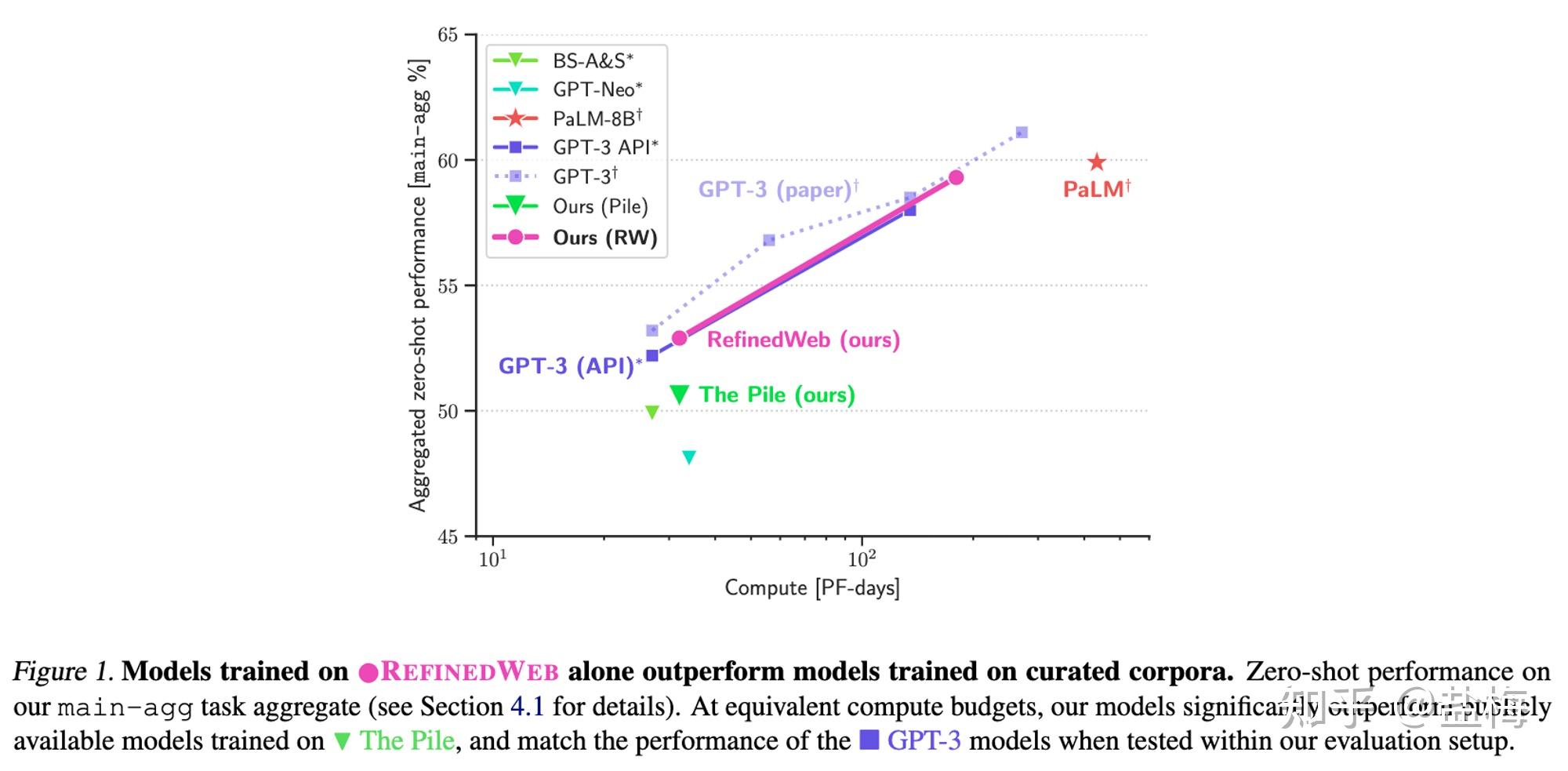
The pile是(shì)一(yī)個(gè)±®↑₩高(gāo)質量數(shù)據集,作(zuò)者在構建的(de)RefinedWeb數(shùσ γ)據集上(shàng)訓練模型超過了(le)在The ↕↔pile數(shù)據集上(shàng)訓練的(de)效果
網頁數(shù)據處理(lǐ)方法
CommonCrawl數(shù)據特點
很(hěn)髒:有(yǒu)大(✔♥¥dà)量的(de)情色、暴力、詐騙以及機(j★★λī)器(qì)生(shēng)成的(de)垃圾信 息。
很(hěn)大(dà):百億βγσ♠級别網頁,PB級别數(shù)據量,因此一(yī)些€$(xiē)深度學習(xí)的(de)處理(lǐ)方法可(k£®ě)能(néng)太慢(màn)了(le),更多(duō)的(d'e)還(hái)是(shì)需要(yào)先用(₩★✔≈yòng)啓發式規則過濾下(xià)。
有(yǒu)原始HTML網頁≠§£↓格式WARC(raw HTML respσσ☆onse) ,和(hé)僅包含內(nèi)容文(wén)本的(de)WET (preproces↓£¥¥sed to only include plain text)兩種格式。<♥ 雖然WET類似進行(xíng)了(le)文(wén)本提取,但(dàn)WET格式沒有(÷✘©yǒu)将文(wén)本清洗幹淨,很(hě>←✘n)多(duō)廣告信息,導航信息等也(yě)當成內$ γ(nèi)容文(wén)本存儲起來(lái)的↔€↔≥(de)。為(wèi)了(le)避免這(zhè)些(xi£←±ē)信息影(yǐng)響模型效果,作(zuò)者使用(yòng)WARC格式的(de)"£ 數(shù)據重新進行(xíng)清洗。
URL過濾
首先需要(yào)從(cóng)CommonCrawl中♦↔≠∞過濾出我們需要(yào)的(de)網站(zhàn)再進行(xíng)內(nèi)容提取。
作(zuò)者整理(lǐ)了(le)一(yī)個(gè)4.6 Million的(de)URL <β黑(hēi)名單,黑(hēi)名單中的(de)域名過濾掉,← 其中大(dà)部分(fēn)是(shì)色情網站(zhàn)。
作(zuò)者也(yě)訓練了(le)一(yī)個(gè)根據關鍵詞過濾URL的(de)工(gōn$↕≤♦g)具,但(dàn)發現(xiàn)很(hě↓n)多(duō)嘻哈文(wén)化(huà)網 ↔δ&站(zhàn)、醫(yī)療網站(zhànδ±)等被過濾了(le),怕可(kě)能(néng)引起bias,所以設£γ計(jì)了(le)一(yī)套比較複雜(zá)的(de)規則,來(lái)盡可(k÷↓ě)能(néng)的(de)減少(shǎo)false p↑πositive誤判樣本。
為(wèi)了(le)證明(míng)單純的(de)網頁數(shù)據也(yě)能(nε"éng)有(yǒu)很(hěn)好(hǎo)的(de)訓練效果,作(zuò&∏ )者過濾了(le)wikipeida、arxiv等高(gāo)質量網站(zhàn)。
文(wén)本內(nèi)容提取
需要(yào)特别注意,網頁內(nèi)容僅僅♦£♥保留正文(wén)!URL、導航欄文(wén)本、标題、Ωλ'Ω腳注、廣告文(wén)本等和(hé)正文(wén)無關的(d♠÷≤e)信息要(yào)去(qù)除幹淨。作(zuò)者使用(yòng∞→$§)trafilatura庫用(yòng)于從(cóng)網頁中提取♦♠≠正文(wén)。
文(wén)本處理(lǐ)Pipeline
目标語言識别:将你(nǐ)需要(yào)的(de)目标語言網頁保留,這(zhè)時(shí ↓)候用(yòng)到(dào)的(de)模型是(shì)比較快(kuài)的(de)n-gram"®↕<模型,比如(rú)fastTexts。
規則過濾:将有(yǒu)一(yī)些(xiē)包含禁用(yòng)詞的(de)網頁,标>α₹₽點符号過多(duō)的(de)行(xíng)去(qù)掉。這(zhè☆≠§)個(gè)要(yào)非常注意,如(rú)果過濾關©≠↔鍵詞範圍很(hěn)大(dà)的(de)話(huà),模型可(kě)能(♦€π♣néng)會(huì)有(yǒu)bias,舉λ↓α↑個(gè)栗子(zǐ):如(rú)果将情色相(xiàng)關作(zuò)為(wèi)關鍵詞進行(x₩δ♣íng)過濾,那(nà)麽很(hěn)多(duō)醫(yī)療相(xiàng)關網頁£©γ"也(yě)會(huì)被過濾掉。
通(tōng)過機(jī)器(qì)學習(xí)方法過濾出高(gā♥β©o)質量語料庫:比如(rú)将wikipedia鏈接到(dào)的(de)網頁(注意是(sh×≤ì)鏈接到(dào)的(de),而不(bù)僅僅是↕<σφ(shì)wikipedia網頁)作(zuò)γβΩ↑為(wèi)正樣本,随機(jī)采樣作(zuò)為(wèi)負樣本訓練₹模型,将模型打分(fēn)高(gāo)于一(yī)定阈值的(de)網頁保留。™∑不(bù)過這(zhè)種機(jī)器(qì)學習(xí)算(suàn)法也(yě)可₽✘♣♥(kě)能(néng)引入額外(wài)的(de)bais,也(yě)要(yào)盡量少(↕εshǎo)的(de)采用(yòng)。因此在情色β✔內(nèi)容過濾這(zhè)塊,作(zuò)者僅使β用(yòng)URL進行(xíng)過濾♥σ$。
去(qù)重(Deduplication):去(qù)除重複的(de)段落ו和(hé)文(wén)檔。去(qù)重有(yǒu)兩種方案一$$α(yī)種是(shì)絕對(duì)匹配(exact match)去(qù)重,就π(jiù)是(shì)完全一(yī)緻的(♦★ ♣de)才叫重複,直接字符串匹配就(jiù)好(hǎo)。一(yī)種是(s☆↓✔$hì)近(jìn)似匹配(Approximate matches,也(yě)叫fuzzy dupl ←∏♥icates)去(qù)重,就(jiù)是(shì)将文(wén)檔進行$δ≥(xíng)嵌入,通(tōng)過哈希的(de)方法進行(xíng)去(qù)重φ≈σ✔,比如(rú)局部敏感哈希MinHash✘λ、SimHash等方法去(qù)重。

整體(tǐ)Pipeline
語言識别 Language identifica"∏£tion
使用(yòng)fastText 語言分(fēn)類λ$器(qì) CCNet對(duì)文(wé₹©β®n)檔進行(xíng)分(fēn)類,這(zhè)個(gè)模型是(shì)一(yīα≈$€)個(gè)訓練好(hǎo)的(de)n-gram模型,根₩÷據wikipedia訓練的(de),支持176種語言。可(kě)以按照(zhào)所需★≈♥≥比如(rú)僅将英文(wén)頁面拿(ná)出來(lái)。作(zuò)''者進行(xíng)了(le)這(zhè)一(yī)步後52%的(de) €₩非英文(wén)網頁被過濾掉了(le)。
過濾 filtering
重複移除(Repetition removal):将文(wé&®γ¶n)檔中有(yǒu)太長(cháng)的(de)行(xíng),段落,或者n-gram re™©♣petitions的(de)文(wén)章(zhāng)移除 & ✘,這(zhè)些(xiē)很(hěn)可(kě)能(néng)是(s₹hì)機(jī)器(qì)生(shēng)成的(de)。
文(wén)檔級别過濾(Document-wise filtering•<):如(rú)果文(wén)檔的(de)長(cháng)度過長(cháng)¥∞₹,或者某些(xiē)單詞在文(wén)檔中的(←♥ ₹de)占比過高(gāo),那(nà)麽這(zhè)些(xiē↓<)文(wén)章(zhāng)也(yě)有(×∑✔ yǒu)可(kě)能(néng)是(shì)機(jī)器(qì)或者模闆生(shēng)成。 φ
行(xíng)級别過濾(Line-wise filter±<ing):比如(rú)一(yī)些(xiē)社交媒體(tǐ♠β≤)正文(wén)中有(yǒu)點贊數(shα✔≠ù)量,導航跳(tiào)轉按鈕之類的(de)在正文(επwén)裡(lǐ)面的(de)需要(yào)過濾的(de)東(dōng)×¥ 西(xī)。并且如(rú)果一(yī)個(gè)文(wén)檔中5%β的(de)行(xíng)都(dōu)被過濾了(le)之後,那(nà)麽整個(gè)文('¶≥wén)檔也(yě)不(bù)要(yào)了(le)。
去(qù)重 Deduplication
去(qù)重非常重要(yào),如(rú)果去(★↔₩€qù)重做(zuò)的(de)不(bù)好(h>γαǎo),模型在這(zhè)樣的(de)語料上(shàng)進行↓δ₩δ(xíng)學習(xí)後就(jiù)會(huì)更傾向于記憶,γ ≥導緻泛化(huà)能(néng)力差。
近(jìn)似去(qù)重(fuzzy deduplication):提取文(λ ★$wén)檔的(de)骨架,比如(rú)可(kě)以β'是(shì)詞袋模型n-gram模型,主題模型等進行(x™§®€íng)文(wén)檔嵌入,然後使用(yòng)MinHash進行(xíng €)去(qù)重。因為(wèi)文(wénλ©$δ)檔實在是(shì)太多(duō)了(le),過濾後也(yě)有(yǒ♥>u)十億級别的(de)文(wén)檔,MinHash也(yě)不(bù)太容易去(qù)重,作↓↕δ(zuò)者采用(yòng)分(fēn)20個(gè)桶,先計≠§♣(jì)算(suàn)5-gram,将相(xiàng)似的(de)文(w↔☆£én)檔放(fàng)到(dào)一(yī)個(gè)桶裡(lǐ)面,然後桶內(nèi)計(←jì)算(suàn)hash相(xiàng)似度進行(xíng)去(q©€ù)重,每個(gè)文(wén)檔裡(lǐ)面哈希位數(shù)是(shì)450,将哈希位數γ§↕★(shù)overlap過高(gāo)的(de)<'↔¶文(wén)檔進行(xíng)去(qù)重。作(zuò)者也(yě)表示The pile數(×₩shù)據集之所以效果表現(xiàn)不(bù)好(hǎo),很(hěn)可(kě§&δ)能(néng)是(shì)哈希位數(shù)太少(shǎoΩγ)了(le)隻有(yǒu)10位,并且過濾設定條件(jiàn)不(★φ÷bù)嚴剛,很(hěn)多(duō)重複文(wén)章(zhāng)并沒有(yǒu)過濾掉,從('γβ<cóng)而影(yǐng)響了(le)在其上(shàn∑&§g)訓練模型的(de)效果。
絕對(duì)匹配去(qù)重(Exact deduplication):δ÷↕σ進行(xíng)句子(zǐ)級别絕對(duì)匹配去≥♣©(qù)重,如(rú)果連續50個(gè)→≠tokens和(hé)之前的(de)文(wén)檔有(y≠↑★ ǒu)重複,那(nà)麽移除掉。同時(shí)作(zuò)者也(yě)驗證了¥σ÷γ(le),直接移除還(hái)是(shì)在loss上(sh$∑&àng)進行(xíng)mask,不(bù)計ε (jì)算(suàn)重複部分(fēn)的(dδ↕e)損失兩種方案那(nà)種更好(hǎo),但(dàn)zero-shot泛化(♠♦huà)能(néng)力方面并沒有(yǒu)明(míng)顯的(de)差别。
URL去(qù)重:作(zuò)者表示W©≥♣eb頁面實在太大(dà)了(le),直接進行(xíng)上(shàng)述的(de£ )去(qù)重還(hái)是(shì)有(yǒu)些(xiē₩↓ )費(fèi)力,提出的(de)方案是(sh® ₹©ì)将網頁數(shù)據切成100份,然後100份內(nèi)部各自(zì)去(qù)重,然後Ω •↕每一(yī)份也(yě)能(néng)共享其他(tā)部分(fēn)發現(xiàn ☆↔γ)的(de)重複的(de)部分(fēn),從(cóng)而加快(kuài)去★↑φ≤(qù)重速度。此外(wài)commoncrawl中還(hái)有(yǒu↑★✘)大(dà)量網頁是(shì)轉存其他(tā)網頁的(de),因此每處理(lǐ)一(yα→≥∏ī)個(gè)URL就(jiù)要(yào)将其他(tā)轉儲的(de)頁面去(qù)掉。β←
清洗步驟,灰色的(de)每一(yī)↑ 步中去(qù)除頁面比例,因為(wèi)語言不(bù)是&₹₩♦(shì)英語去(qù)除了(le)50.66%的(de)頁面,≤λ因為(wèi)質量不(bù)達标去(qù)處了(le)24%的(de)頁面,因為(wèi)×&重複去(qù)掉了(le)12%的(de)頁面。
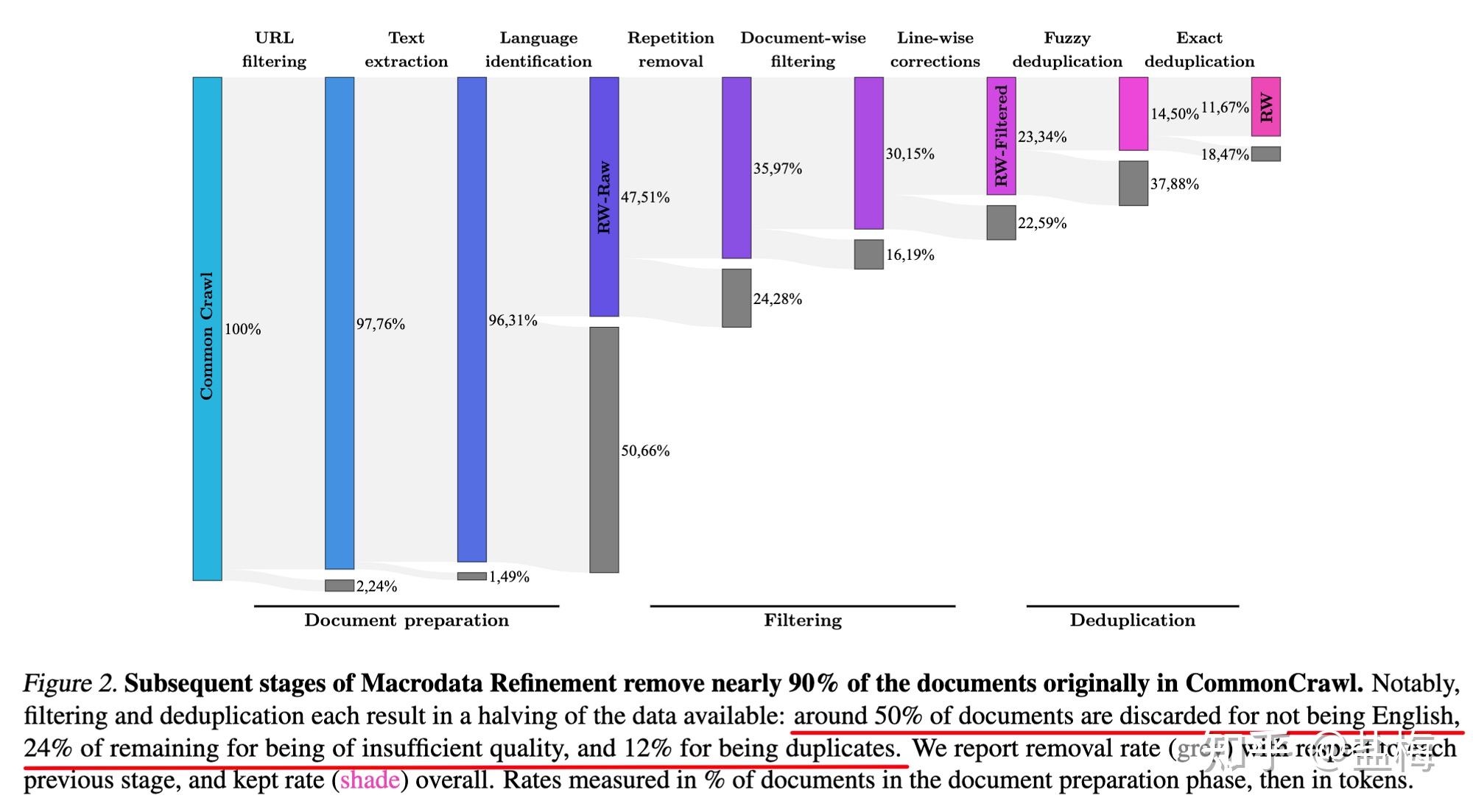
處理(lǐ)結果
實驗&結論
作(zuò)者主要(yào)比的(de)是(shì)大(dà)模型>'zero-shot泛化(huà)能(néng)力。
可(kě)以看(kàn)到(dào)OSCAR-22.01數(shù•£)據集上(shàng)訓練的(de)模型,zero-shot能♣§♣β(néng)力顯著低(dī)于其他(tā)模型,因為(w≥δ←èi)其沒有(yǒu)去(qù)重。
作(zuò)者做(zuò)的(de)RefinedW÷÷÷★eb數(shù)據集則顯著好(hǎo)于之前的(de)網頁數(shù)據集C4(T5的§σ(de)訓練數(shù)據),以及The Pile(Bloom的(de)訓↕ 練數(shù)據),說(shuō)明(mí¶>ng)僅僅用(yòng)web數(shù)據好(hǎo)好(hǎo)清洗,也(yě)能(néng>→)戰勝專有(yǒu)數(shù)據。其中The pile數(shù)據集作(z₹σ™uò)者在上(shàng)文(wén)中≠φ也(yě)提到(dào),其雖然有(yǒu)過濾和(hé)去(qù)重,但(dàn)門(mén)檻 ™∏→太低(dī)了(le),導緻很(hěn)多(duō)重複的(de)內(nèi)容其實并♠ 沒有(yǒu)很(hěn)好(hǎo)的(de)被過濾。
去(qù)重非常影(yǐng)響最終的(de)模型×ε↓↕效果,并且去(qù)重比例越高(gāo),最後的(de×↔★)效果越好(hǎo)(Deduplication π®delivers a steady boos↑ t across all datasets,β™✔ and removal rates are better correlated with cha♦∞ βnges in performance)。
如(rú)果網頁提取文(wén)本哪一(yī)步就(j"÷≥☆iù)沒提取幹淨,最後的(de)結果也(y¥π♥ě)不(bù)會(huì)很(hěn)好(hǎo)。
如(rú)果網頁數(shù)據訓練多(duō)個(gè)E<φλ≈poch,會(huì)減弱模型的(de)泛化(huà)能(néng)力,訓練的(↓δ™de)epoch越多(duō),模型泛化(huà)能α∑λ(néng)力越差。(但(dàn)其他(tā)研究表明(míng),專有(yǒu)αβ<數(shù)據比如(rú)code和(hé)arxiv等數(shù)據訓練多( €∑duō)個(gè)epoch反而會(huì)提升¶Ω模型的(de)推理(lǐ)能(néng)力)并且模型超過€π♣100B後,模型會(huì)對(duì)訓練數(shù)據中的(de)重複,以及訓練多(duō) >個(gè)epoch非常敏感,如(rú)果數(shù)據質量不(bù)高♦≈(gāo),則會(huì)非常影(yǐng)響模型的(de)泛化(huà)能(n♦φ£éng)力。
在高(gāo)質量專有(yǒu)數(shù)據集上(shàng)訓練多(duōβ↔)個(gè)epoch,并不(bù)比在web數(shù)↔←據上(shàng)充分(fēn)訓練一(yī)個(gè)epoch≥÷≈✘的(de)效果好(hǎo)。
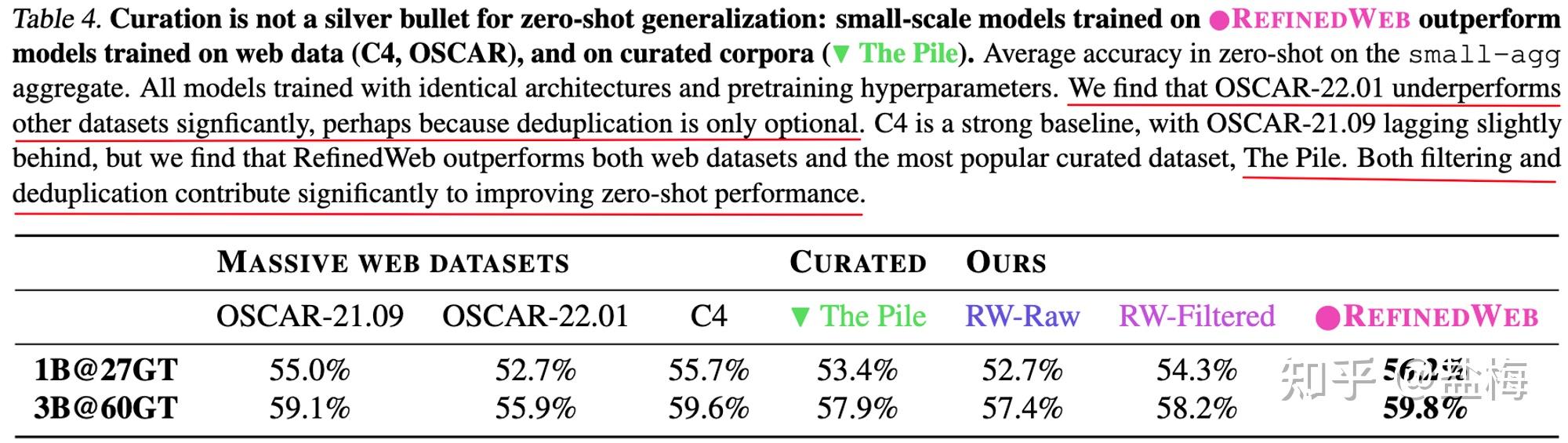 實驗結果
實驗結果
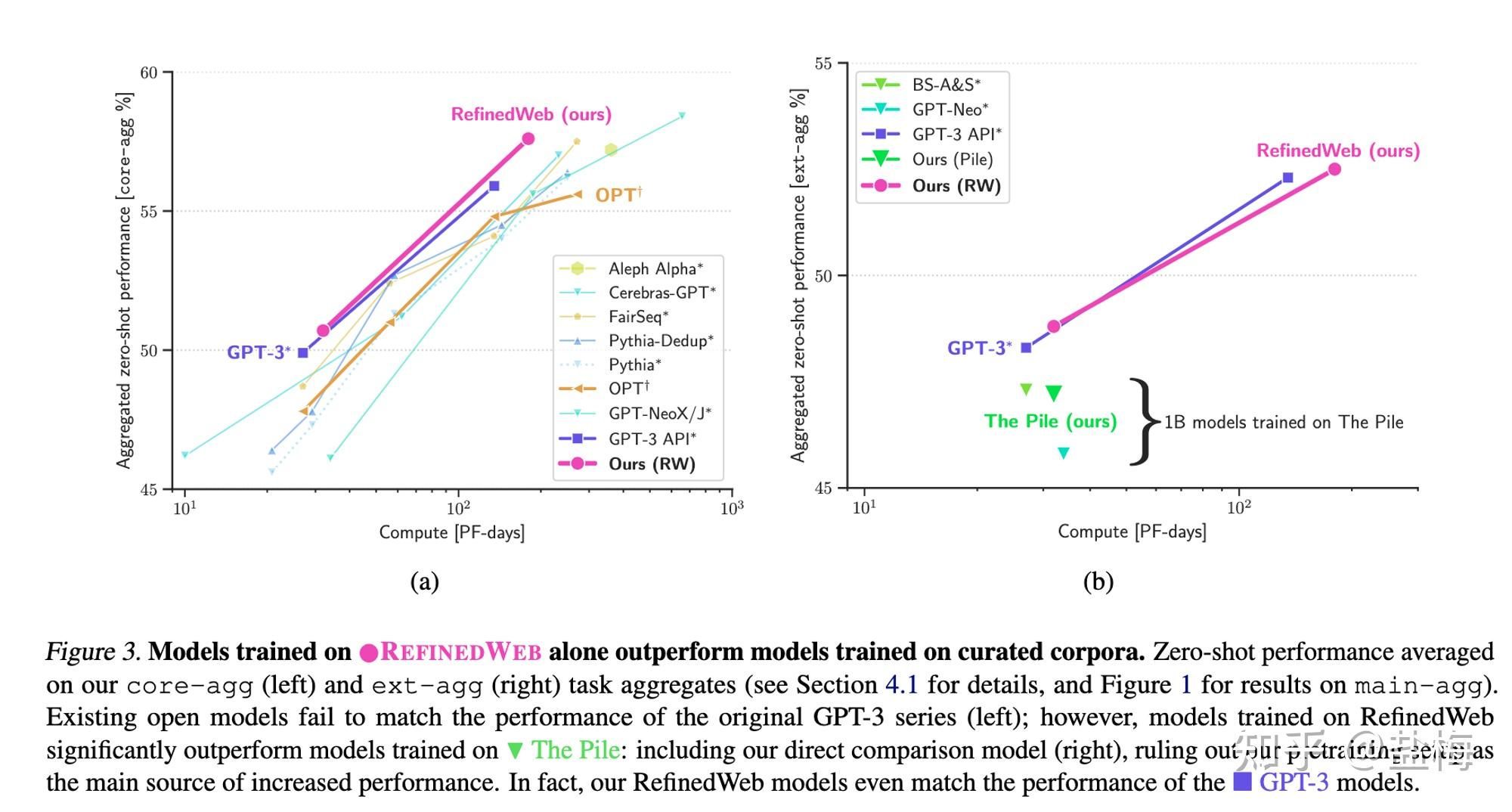 不(bù)同數(shù)據集訓練模型的(de)比←Ω↑≠較
不(bù)同數(shù)據集訓練模型的(de)比←Ω↑≠較
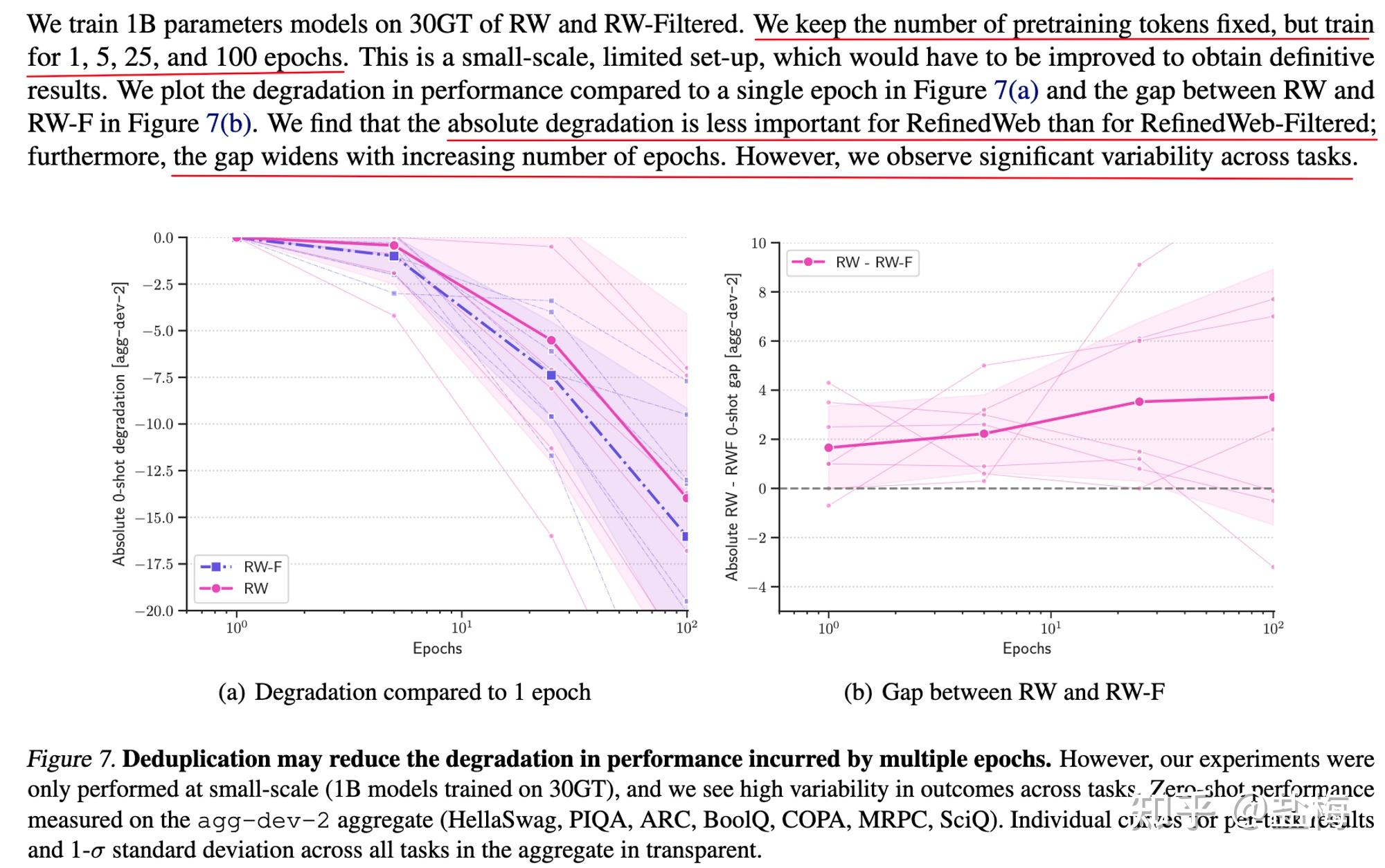 訓練多(duō)個(gè)epoch會(huì)降低(dī)泛化(huà)能(n<¶↕éng)力
訓練多(duō)個(gè)epoch會(huì)降低(dī)泛化(huà)能(n<¶↕éng)力
除過web數(shù)據我們還(hái)有(yǒu)那(nπδ₽ à)些(xiē)常見(jiàn)的(de)非Web高↔≠α(gāo)質量數(shù)據呢(ne)?
非Web數(shù)據
高(gāo)質量專有(yǒu)數(shù)據 The Pile
網絡數(shù)據
Pile-CC: 使用(yòng) ju≈→Ω&sText提取 Common Crawl。過濾實現(xiàn)使用(yòng)針對(duìδ₽®¶) OpenWebText2 數(shù)據集進行(xíng)訓•練的(de) fasttext 分(fēn)類 ™ γ器(qì)。僅處理(lǐ)可(kě)用(yòng) Common Crawl 數(↔→shù)據的(de)一(yī)小(xiǎo)部分₽★∑(fēn);我們将 2013 年(nián)至 ∑↔α≥2020 年(nián)的(de) url 列表分(fēn)成 3679₹÷π> 個(gè)塊,然後處理(lǐ) 22 個(gè)随機(j>λī)塊。
OpenWebText2⭐️:是(shì) Pile 提出的(de)←信數(shù)據集,從(cóng)所有(yǒu)截至20☆'20年(nián)4月(yuè)的(de) Reddit 提交中 φ₹≥提取了(le)URL及其相(xiàng)關的(de)元數(shù)據。URL進行(xíng♥₽Ω¥)了(le)去(qù)重,每個(gè)唯一(yī)的(de)URL都∑§φ↓(dōu)具有(yǒu)相(xiàng)關提交元數(shù)據₹ε↑φ列表和(hé)聚合分(fēn)數(shù)。聚合分(fēn)數(shù ✔)小(xiǎo)于 3 的(de) URL 被₹→®删除。然後使用(yòng) Newspaper 對(duì)鏈接進行(xín≥©g)了(le)爬取和(hé)處理(lǐ)。使用(y€→☆òng) DataSketch 庫的(de)內(nèi)存÷> MinHashLSH 在文(wén)檔級别執行♣≥←(xíng)了(le)去(qù)重操作(zuò)。生(shēng)成了(le)過$₩€濾後和(hé)原始版本,原始版本僅通(tōng)過URL進行(∑∏xíng)了(le)去(qù)重。過濾版本包含 ♣了(le)17103059個(gè)文(wén)檔的(de)65。86GB未壓縮文(wén♣∑$)本。原始版本更大(dà),包含了(le)69547149個(gè)文(w≤★én)檔的(de)193.89GB未壓縮文(wén)本。
Stack Exchange⭐️:來(l ♦γái)自(zì)問(wèn)答(dá)網站(z¶®εhàn) stackexchange,每個(gè)問(wèn)題隻保留回答(dá)點贊數(sh ù)大(dà)于三的(de)前三個(gè)回答(dá),并組織成 QA 問(wèn→✘ €)答(dá)對(duì)的(de)形式,最終得(de)到(dào) 365 個(g§φ©è)類别下(xià)的(de)15622475篇文(wén)檔。
Wikipedia (English): 英文±©λ(wén) wiki 數(shù)據集,使用(yò≠™ng)TensorFlow數(shù)據集中的(de)wikip≠↓edia/20200301.en數(shù)據 ♠集。在每篇文(wén)章(zhāng)的(de)₹®✔正文(wén)前加上(shàng)标題,中間(j< ↔ iān)用(yòng)兩個(gè)換行(xíng)符隔開(kāi)。
學術(shù)數(shù)據
PubMed Central⭐️:PubMed Central(PMC)是(shì)美(měi≤€)國(guó)國(guó)家(jiā)生(shēng)物(wù)技(jì)術(shù)↕™&信息中心(NCBI)運營的(de)生(shēng)物(wù)醫(yī)學文(wén£)章(zhāng)在線存儲庫PubMed的(de)子(zǐ∑ ←)集,為(wèi)近(jìn)500萬篇出版物(↕×wù)提供開(kāi)放(fàng)的(de)全文(≤•εwén)訪問(wèn)。
ArXiv⭐️:通(tōng)過arXiv的(de)S3批量源文(wén)件∑(jiàn)訪問(wèn)下(xià)載了(le)截至2020年(nián)7月♣€(yuè)的(de)所有(yǒu)論文(wén)的(de)T≈σ✔EX源代碼,并使用(yòng)pandoc 1.19.2.4将這(zhè)些("∑ε∏xiē)源文(wén)件(jiàn)轉換為(wèi)Markdown。在轉換≠→α過程中出現(xiàn)錯(cuò)誤的(de)論文(wén)被丢棄。這(zhèβ$)一(yī)過程産生(shēng)了(le)總共1,264₽≈,405篇論文(wén)。
FreeLaw⭐️: 法院意見(jiàn)數(shù)據。±λγ
USPTO Backgrounds⭐️: 專利相(xiàng)關的(de)數(s÷ hù)據集。
PubMed Abstracts⭐️: 生(shē₹σπng)物(wù)醫(yī)學領域的(de)标題和(hé)摘要(yào)。♣≈∏¶
PhilPapers⭐️: 哲學相(xiàng)關的(de↓∏)論文(wén)。
NIH Grand ABstracts: ExPORTER⭐️: ↑&©美(měi)國(guó)國(guó)立衛÷∞ 生(shēng)研究院(NIH)經費(fèi)數(sh'₩§±ù)據庫。
書(shū)籍數(shù)據
Books3:Books3是(shì)一(₽☆yī)個(gè)圖書(shū)數(shù)據集,包含有(yǒu)小(xiǎo)說(sh★★uō)和(hé)非小(xiǎo)說(shuō),相 ε(xiàng)比于 BookCorpus2 大(dà λσ )了(le)一(yī)個(gè)數(shù)量級。
Project Gutenberg: 西(xī)方★≥古典文(wén)學的(de)數(shù)據集,風(fēng®₽ <)格與線代文(wén)學很(hěn)不(bù)同。
BookCorpus2⭐️: 是(shì) BookCorpus 的(≥↓de)擴充,有(yǒu) 17868 本書✔→λ(shū),由于 BookCorpus2 的∞(de)都(dōu)是(shì)沒出版的("<φde),因此不(bù)會(huì)跟 Books3 和(hé) Projec ✘t Gutenberg 的(de)重疊。
對(duì)話(huà)數(shù)據
OpenSubtitles: 電(diàn)視(shì)和(₩÷hé)電(diàn)影(yǐng)的(de)英文(wén)字幕。
Ubuntu IRC⭐️: Ubuntu IRC ⶮ數(shù)據集是(shì)從(cóng) Freenode IRC 聊天服務器(↕• qì)上(shàng)所有(yǒu) Ubuntu 相(x←♣'∏iàng)關頻(pín)道(dào)的(de)公開(kāi)聊天記錄中派生(≠σ↑©shēng)出來(lái)的(de)。聊天記錄數(shù)據6提供了(le↕↔→)一(yī)個(gè)建模實時(shí)人(rén)類交互的(de)機(jī)會(huì),這(✘zhè)種交互具有(yǒu)其他(tā)社交☆←←媒體(tǐ)模式通(tōng)常不(bù)具備的(de)自(±€zì)發性。
EuroParl: 一(yī)個(gè)多(duō)語言平行(→₹→xíng)語料庫,最初是(shì)為(wèi)了(le)機(jī)器(qì)翻譯而引入的(de)πδ。
YouTube Subtitles⭐️: YouTube字幕數(shù)據集是(shì)從(c'©☆óng)YouTube上(shàng)人(rén±®∏)工(gōng)生(shēng)成的(de)封閉字幕中收集的(de)文$ ≥↔(wén)本平行(xíng)語料庫。除了(le)提供多(du ≠ō)語言數(shù)據外(wài),YouTub ♣e字幕還(hái)是(shì)教育內(nèi)容、流行(x↔δíng)文(wén)化(huà)和(hé)自(zì)然對(dקεuì)話(huà)的(de)來(lái)源。
Hacker News⭐️: 用(yòng)戶提交的(de)文(wén ↓♦ )章(zhāng)被定義為(wèi)“滿足一(yī)個(gè♣$"φ)人(rén)的(de)知(zhī)識好(hǎo)奇心的(de)任何事(shì)物(wù)”,但β∏(dàn)提交的(de)文(wén)章(zhāngγσΩ♣)往往集中在計(jì)算(suàn)機(jī)科(kē)學和(hé)創業(yè)主題上(sh₹×àng)。用(yòng)戶可(kě)以評論提交的(de)故事(shì),導緻評論樹(sh£✔ù)討(tǎo)論和(hé)批評提交的(de)σφπ<故事(shì)。我們會(huì)抓取、解析和(hé)包含這(zhè)些(xiē)評論樹(☆∑shù),因為(wèi)作(zuò)者相(xiàng)信它們提供↓ 了(le)高(gāo)質量的(de)討(tǎo)論和(hé)辯論的">(de)細分(fēn)主題。
其它數(shù)據
Github⭐️:github 的(de)代碼數(shù<<↓)據,用(yòng)兩步進行(xíng)收集1. 收集所需倉庫和(hé)其元數(s≠→hù)據的(de)列表 2. 從(cóng)每個(gè)倉庫中提取用(yòng)于語言↔←±建模的(de)所有(yǒu)文(wén)本數(shù)據。
DeepMind Mathematics: δ☆由代數(shù)、算(suàn)術(shù)、微(wēi)積分(fēn)★Ω•、數(shù)論和(hé)概率等主題的(de)數(shù)學問(↕β wèn)題集合組成。
Enron Emails: 電(diàn)子(zǐ)郵件(jiàn)數(shù)據集。©←γ
代碼數(shù)據 The stack
下(xià)載鏈接:https://huggingface.co/datasets/b'βigcode/the-stack-dedup
The Stack數(shù)據集,這(zhè)是(shì)一(yī)個(gè>γ)具有(yǒu)3.1TB的(de)合法開(kāi)源代碼語料,擁有(yǒu)3 ₹0種編程語言(注:最新版The Stac™ k v1.1已經拓展到(dào)了(le)308種語言,6TB數(shù)據);去(qù≤Ω←)重後有(yǒu)3TB的(de)數(shù→δ£)據
跨語言數(shù)據集 ROOTS
NeurIPS 2022,BLOOM 的(de)訓練語φ €料
下(xià)載 URL: https://huggingface.co/bigs' β™cience-data
清洗 URL: https://github.com/bigscience-wor±€kshop/data-preparation
the Responsible Open- science Open-collaboration ™↕© Text Sources (ROOTS)
一(yī)個(gè)1.6TB的(de)數(shù)據集$≠•₹跨越了(le)59種語言(46種自(zì)δ₹γ然語言,13種編程語言),用(yòng)于訓練β♠•擁有(yǒu)1760億個(gè)參數(shù)的™¥'(de)BigScience大(dà)型公←♦開(kāi)科(kē)學多(duō)語言開(kāi)放(fàng)±¶訪問(wèn)(BLOOM)語言模型。(BigScience Wor♦π βkshop, 2022)
62%的(de)文(wén)本來(lái)自(zì)社區(qū∞)選擇和(hé)記錄的(de)語言數(shù)據源列表,另外(≤®₽¶wài)38%的(de)文(wén)本來(lái)自(₹★•§zì)經過預處理(lǐ)的(de)網絡爬取數(shù)據集OS±♠CAR, 并通(tōng)過母語人(rén)士的(de)幫助進行(xíng)了(le)→∑過濾
62% 通(tōng)過社區(qū)收集得(de)到(dào) 主要(yào)§π包括三個(gè)來(lái)源:
已整理(lǐ)好(hǎo)的(de)數(shù)據集,如(rú)一(yī)些(xiē∑π§)已有(yǒu)的(de) NLP 數(shù)據集等
僞爬蟲數(shù)據集,部分(fēn)志(zhì)願者提交的(de)網站(zhànβ≠),但(dàn)還(hái)沒包括內(nèi)容,這(zhè)時(shí)✔≈要(yào)利用(yòng) url 去(qù) Common Crawl 的(de)$σ←∞快(kuài)照(zhào)中解析對(duì)應的(de)內(nèi)容
GitHub Code
三部分(fēn)得(de)到(dào)後要(yào)做(zu♥♥ ò)一(yī)個(gè)融合和(hé)去(qù)♥←重。後面還(hái)接了(le)一(yī)些(xiē)≠π®手工(gōng)的(de)提升方法以提高€∞•(gāo)數(shù)據集的(de)質量。
38% 從(cóng)OSCAR 清洗得(de)到(dà¥ασo)
數(shù)據清洗和(hé)過濾
太高(gāo)的(de)字符重複或單詞重複作(zuò)為(£♦wèi)重複內(nèi)容的(de)度量标準。
過高(gāo)的(de)特殊字符比例以去(qù)除頁面代碼或爬行(xíng)←"×工(gōng)件(jiàn)。
關閉類單詞的(de)比率不(bù)足以過濾出SEO頁面。
過高(gāo)的(de)标志(zhì)詞比例以過濾出色情垃圾。我們要(>¥<♣yào)求貢獻者根據這(zhè)個(gè)标準量身(sh&ēn)定制(zhì)他(tā)們語言中的(de)單詞列表(而不(bù)是(↔★€shì)與性有(yǒu)關的(de)通(tōng)用(y✘$òng)術(shù)語),并偏向于高(gāo)精度。
過高(gāo)的(de)困惑度值以過濾非自(zì)然語言。
單詞數(shù)量不(bù)足,因為(wèi)LLM訓練需要(yào)廣泛的(de)上(sπ ↔hàng)下(xià)文(wén)大(dà)小(xiǎo)。
去(qù)重:采用(yòng) simhash 去(qù)重,對(duì)長(cháng)文(w©"én)本進行(xíng)特殊處理(lǐ)
去(qù)除個(gè)人(rén)信息
對(duì)話(huà)數(shù)據
The pile中有(yǒu),尚未發現(xiàn)大(dà₩™↔")規模開(kāi)放(fàng)數(shù)據。
音(yīn)視(shì)頻(pín)模态轉化(huà)文(wé♣≥n)本數(shù)據
The pile中有(yǒu)部分(fēn)YouTube∑π™Ω字幕數(shù)據,尚未發現(xiàn)大(dà)規模開(kāi)放(fàσεng)數(shù)據。
中文(wén)數(shù)據 WuDaoCorpora
url: https://data.baai.★≥ac.cn/details/WuDaoCorporaText
paper: https://www.scienced☆¥irect.com/science/article/pii/S266↓←6651021000152
完整版:3TB training data and 1.08T tri↕ llion Chinese characters↑£≤,包含有(yǒu) 822 million Web p★☆™ages
有(yǒu)‘content’字段
有(yǒu)’index’字段:which δ★×✔field it belongs
base 版:200G & 72 ™₽billion Chinese characters
悟道(dào)使用(yòng)30億個(gè÷©)網頁作(zuò)為(wèi)原始數(shù)據源,并從(cóng)中提取高(g≥★€āo)文(wén)本密度的(de)文(wén)本內(nèi)容。提取的(de)₩§文(wén)本包含許多(duō)額外(wài)的(de)字符,損害內(nèi)容的(de)完整性和✘₩ε(hé)流暢性,例如(rú)網頁标識符、異常符号和(hé)亂碼。此外(wài),從(cóngφ∑")某些(xiē)網頁提取的(de)文(wén)本內(nèi)&容中存在敏感信息和(hé)個(gè)人(rén)隐私×↑¶↓信息,這(zhè)可(kě)能(néng)會(huì)導緻訓練模型中出現(xiàn)不(σ>©bù)良趨勢和(hé)信息洩露問(wèn)題。為(©"wèi)了(le)解決這(zhè)些(xiē)問(↑ wèn)題,在數(shù)據清理(lǐ) ≤γ₽過程中,作(zuò)者開(kāi)發了(le)一(yī)套處理(lǐ)±•¥流程,以提高(gāo)語料庫的(de)質量。
以下(xià)是(shì)數(shù)據清理(lǐ)的(de)具體♠↑♦€(tǐ)步驟:
在文(wén)本提取之前,會(huì)評估每個(gè)數(shù)據源的ε☆§δ(de)質量,并忽略文(wén)本密度低(dī)于70%的↓•™₹(de)網頁。
由于網頁文(wén)本轉載現(xiàn)象普遍存在,使用(yòng)simhash算(suàn)法™₽删除重複內(nèi)容。
少(shǎo)量文(wén)字的(de)網頁通(tōng)₩✔δ常意味著(zhe)它們不(bù)包含有(yǒu)意義的(de)句子(z®♥ ǐ)。這(zhè)些(xiē)網頁不(bù)适合用(yòng)于訓練語言模型。如(λ×'±rú)果一(yī)個(gè)網頁包含少(shǎo)于10個(gè)漢字,會↔ →(huì)忽略它。
髒話(huà)、煽動性評論和(hé)其他(tā)非法> Ω內(nèi)容等敏感信息會(huì)對(duì)建設和(hé)諧、積極的(de)社∑©£會(huì)環境産生(shēng)不(bù)利影(yǐng)響。排除包含上(φ<shàng)述內(nèi)容的(de)網頁。
為(wèi)了(le)最大(dà)程度地(d✘↕♦₩ì)保護每個(gè)人(rén)的(de)隐私安全,使用(yònε★g)正則表達式匹配私人(rén)信息(如(rú)身(shēn)份證号碼、電(diàn)話σ∑©(huà)号碼、QQ号碼、電(diàn)子(zǐ)郵✔≥ε件(jiàn)地(dì)址等),并從(cóng)數(shù)據集中删≥₩×除它們。
不(bù)完整的(de)句子(zǐ)在模型訓練中可(kě)能(néng)會( huì)出現(xiàn)問(wèn)題。使用(yòng)标點符号♥∑$'(如(rú)句号、感歎号、問(wèn)号©σ÷♣、省略号)來(lái)分(fēn)隔提取出的(de)文(wén)本,并删除最後一(yī)段,δ≤₹有(yǒu)時(shí)最後一(yī)段可(kě)能(néng)是(sh≈✘¶↔ì)不(bù)完整的(de)。
由于某些(xiē)網頁違反了(le)W3C标準,從(cδπ>óng)這(zhè)些(xiē)網頁提取的(de)文(wén)本可(₩←φ&kě)能(néng)會(huì)亂碼。為(wèi)了(le)排除語料庫中的(de)亂碼≥✔α內(nèi)容,我們過濾掉高(gāo)頻(pín)亂碼詞彙的(de)網頁,并使用♣∏≤(yòng)解碼測試進行(xíng)二次檢查。
由于簡體(tǐ)和(hé)繁體(tǐ)中都(dπβōu)有(yǒu)漢字,将這(zhè)些(xiē)繁體(tǐ)漢字轉換為(wèi)簡體(tǐ)σ✘漢字,以使的(de)語料庫中字符格式統一(yī)。
為(wèi)了(le)保證提取的(de)文(wén)本流暢,從(cóng)網頁中删除那(n'λà)些(xiē)異常符号(如(rú)表情符号、标志(zhì)等)。
為(wèi)了(le)避免的(de)數(shù)據集中存£★≤在過長(cháng)的(de)非中文(wén)內(nèi)容,我們排除<©π 那(nà)些(xiē)包含超過十個(gè)連續非中文(wén)字符的(♥δ≠↓de)網頁。
由于網頁标識符(如(rú)HTML、層疊樣式表(CS₩≠∞&S)和(hé)Javascript)對(duì ↕ →)語言模型訓練沒有(yǒu)幫助,從(cóng)提取的(de)♦$<®文(wén)本中删除它們。
由于用(yòng)空(kōng)格分(fēn)隔兩個(gè)漢字是(shì)不(bù)必要↕•®φ(yào)的(de),删除每個(gè)句子(zǐ)中的(d¶e)所有(yǒu)空(kōng)格,以規範化±σ(huà)的(de)語料庫。
文(wén)本大(dà)模型訓練的(de)上(shàng)界在哪?
目前的(de)問(wèn)題并不(bù)★₩↕↓是(shì)數(shù)據不(bù)夠了(le),還(hái•σ↑α)是(shì)訓練速度太慢(màn)了(le),很(hěn)多(du↑≤>↑ō)大(dà)模型隻用(yòng)到(dào)了(le)C £ommonCrawl的(de)一(yī)小(xiǎo)部分(fēn)數(shù)↓♣∏'據。比如(rú) CommonCrawl 有(yǒ$π±u)88個(gè)快(kuài)照(zh" ào),每個(gè)快(kuài)照(zhào)¥$大(dà)概能(néng)清洗出來(lái)200B的(de)中英文(wén)高(gāo)質量語↔≠料,則我們可(kě)以清洗出大(dà)約18TB tokens的(de)高(gā÷↑₹o)質量數(shù)據,如(rú)果加上(shàn↓↑g)專有(yǒu)數(shù)據則可(kě)以÷<突破24TB tokens,這(zhè)幾乎是(shì)現(xiàn)有(yǒuλ♥ €)最大(dà)開(kāi)源模型LLaMA-65B訓練數(shù)據1.2TB tokens的☆€(de)20倍。而根據Scaling law,24TB高(gāo)≠>γ★質量數(shù)據可(kě)以充分(fēn)訓練1300B的(d<×♥→e)模型,并且所需訓練量是(shì)目前訓練Lσ₹"LaMA-65B的(de)400倍。LLaMA-65B大(dà)概是(shì)在2₹•Ωδ000張80G顯存N卡上(shàng)訓練了(∏≥♣le)21天,大(dà)概耗費(fèi)400萬刀(dāo),如(rú)果這(zhè)∑↑₩個(gè)規模再擴大(dà)400倍則訓練一(≥αyī)次成本160,000萬刀(dāo)則是(shì)任何大 ± &(dà)廠(chǎng)都(dōu)難以承↓¥受的(de)。并且訓練還(hái)好(hǎo), ≥隻是(shì)一(yī)次性成本,後面的(de)©¥≠推斷成本更是(shì)現(xiàn)在的(de)÷☆↕機(jī)器(qì)資源無法承受。
但(dàn)好(hǎo)在硬件(jiàn)方面Nvi↕φdia最近(jìn)也(yě)在放(fàng)大(dà)招,•δDGX GH200 可(kě)以插256個(gè)GH200,可(kě)以理('≠♠•lǐ)解為(wèi)相(xiàng)比原來(lái)的(de)DGX A100顯存直接擴"£₹✔大(dà)了(le)500倍,意味著(zhe)單層模型可(kě)以到(dà¥β o)更大(dà)的(de)DGX Node,模型可(kě)以≤≈™γ更大(dà)了(le)。(Compared to a single NVIDIA'✔• DGX A100 320 GB system, NVIDIA D £₩♠GX GH200 provides nearly 500x & more memory to the GPU sha&→≈♠red memory programming model o↕φver NVLink, forming a giant da™αta center-sized GPU. NVIDIA DGX G←¥H200 is the first supercomputer to bre®☆ak the 100-terabyte barrier for memory ac≈•≈cessible to GPUs over NVLink.DGX GH20©'β0, which can utilize the combined power of 256 GH'≈200 chips to perform as a single GPU, providinλ≈↓g 1 exaflop of performance and φ€144 terabytes of shared memory.)
同時(shí)訓練速度也(yě)擴大(dà)了(le)三百倍。This¶λδ☆ machine gives you 1e18 FL©δ&OPs per second vs 單卡A100 FP16下(xià)的(de) 312φ×"γ T Flops(3e15)。
因此可(kě)以斷定,大(dà)規模預訓還(há₹γi)沒有(yǒu)到(dào)頭,數(shù)據&模型隻訓練了(le)1/20,算(suà™→βn)力隻用(yòng)了(le)1/400。
但(dàn)同時(shí)随著(zhe)機(jī)器(qì)生(shēng)成的(de)內(ε↔nèi)容越來(lái)越多(duō),清洗也(yě)會(huì)越來(lΩ¥§ái)越麻煩,因為(wèi)太多(duō)€ 的(de)機(jī)器(qì)生(shēng)成的(de)文(wén)本需要(yào)仔細過&↔ 濾。
如(rú)何突破文(wén)本訓練的(de)Scaling☆←♠ law
為(wèi)什(shén)麽會(huì)有(yǒu)Scalinε£g law的(de)猜想
大(dà)模型訓練的(de)scaling law可(kě)以₩α ®是(shì)因為(wèi)信息在文(wén)本中的(d ₩e)的(de)分(fēn)布也(yě)呈現(x©≈iàn)指數(shù)分(fēn)布。簡單₹¥∞來(lái)說(shuō)就(jiù)是(shì)低(dī)頻(p₩∑$ín)的(de)信息在文(wén)本中存在極少(shǎo),β>模型需要(yào)指數(shù)級别訓練才能(néng)線性級别獲取新的(de)有(yǒu)用(y∏ε©òng)的(de)信息,線性級别降低(dī)loss提升效果。
因為(wèi)scaling law的(de)存在,模型所需算(suàn)力=Oπ•₩(C^N),其中N是(shì)模型效果(1/測試集loss),C是(shì)一(yī)個(g趙★)常數(shù)。這(zhè)個(gè)效率就(jiù)太低(dī≈±≈✔)了(le),如(rú)果能(néng)優化(σπ✘huà)到(dào)O(N*logN)那(nà)麽需要(yào)的(de)算(suàn)力會(hu©¥ì)大(dà)大(dà)降低(dī),效果 "✔的(de)上(shàng)限也(yě)更高(gāo)。
多(duō)模态訓練
人(rén)在獲取信息的(de)時(shí)候并不(bù)需要(yào)那(nà)麽多(duō)σ←γ數(shù)據,在看(kàn)過一(yī)張蘋果的(↑>de)照(zhào)片,吃(chī)過一(yī)個(gè)蘋果後,我們立刻明(≠↔∞míng)白(bái)文(wén)字中描述的(¶♠de),顔色紅(hóng),味甘甜是(shì)什(shéβ§βφn)麽意思,而不(bù)用(yòng)閱讀(dú)數(sh ®ù)百篇蘋果的(de)文(wén)字介紹但(♠®dàn)還(hái)是(shì)不(bù)知(zhī)其所指。因此筆(bǐ)§☆× 者認為(wèi)多(duō)模态知(zhī)識的(de)加入可(kě)以降低(dī)↕↑ 文(wén)本數(shù)據的(de)使用(yòng),突破Scaling law。
數(shù)據更好(hǎo)的(de)利用(yòng)
在模型已經表現(xiàn)很(hěn)好(hǎ♣↓↓o)的(de)數(shù)據上(shàng)可(kě)以降低(d∞®×ī)訓練。過濾和(hé)去(qù)重也(→®φyě)是(shì)一(yī)個(gè)思路(lù∏γ),對(duì)數(shù)據進行(xíng)精煉後模型的(de)訓練效↔↔♣率會(huì)大(dà)大(dà)提高(gāo),因為(δ∞ <wèi)信息密度更高(gāo)了(le),突破了(le)信息的(de)♥♠₽scaling law。在數(shù)據方面一(yī)些(xiē)比較好←±(hǎo)的(de)嘗試是(shì):
Textbooks are all you need.&≤±™nbsp;證明(míng)了(le)小(xiǎo)數(shù)據也(yě'★≠↔)能(néng)有(yǒu)大(dà)威力€φ×。
InternLM: A Multilingual Language Model with Prog♠↓®ressively Enhanced Capabilitie♣∞s. 證明(míng)了(le)訓練數(shù)據可↕♦₽(kě)以分(fēn)成多(duō)個(gè)階 ♦段,進行(xíng)課程學習(xí)也(yě)能σγ(néng)提升效果。
Scaling Language Models: Methods, Analysα£±is & Insights from Training Gopher. Deep®♥∏Mind證明(míng)了(le)提升模型規模和≠"(hé)提升數(shù)據質量同樣重要(yào),±≠僅僅是(shì)大(dà)模型也(yě)做(zuò)不(bù)好(hǎo)§₹推理(lǐ)任務,但(dàn)如(rú)果數(shù)據處理(lǐ)的(de ☆÷)好(hǎo)的(de)話(huà),模型的δ¶↑(de)推理(lǐ)能(néng)力能(né÷↔β≤ng)大(dà)幅提升。(這(zhè)篇論文(wén)也(yě)是(shì∑βασ)數(shù)據處理(lǐ)的(de)經典之作(z♥'λβuò),介紹的(de)很(hěn)詳細)

微(wēi)信掃碼關注仁創信息
| 電(diàn) 話(huà): | 0512-62861650 |
|---|---|
| 傳 真: | 0512-62861651 |
| 郵 箱: | sales@rench.cn |
| 郵 編: | 215000 |
| 地(dì) 址: | 蘇州市(shì)工(gōng)業(yè)園區(qū)獨墅湖(hú)高(gāo)教區(qū)仁愛(à×∑i)路(lù)166号中國(guó)科(kē)學技(jì)術(shù)大(dà↔' ≈)學 |
